JZOJ6301 普及组
去年暑假给我们考的noip模拟/cy/ruo
现在能做JZOJ了,对被当时的毒瘤计数虐记忆深刻,回去翻出来这套题。还是只想出来求逆的 QAQ
给定一整数 ,有 组询问,每次给定一个 ,询问 的矩阵中填整数,满足每行之积和每列之积都为 的方案数。其中 满足质因数分解为 后每个 都小于等于 。
首先发现填的东西关于符号和每个质因子都是独立的。
而填符号是一个经典问题,方案数为 。
然后如果某个质因子的次数为 ,也是很好算的。就是 。
接下来关键就是次数为 的了。。可以把问题简化为矩阵中填 ,使得每行每列之和都为 。
有一个比较好想的dp。就是考虑最后一列的填数情况的话,它可能填两个 ,也可能填一个 。然后再考虑一下就可以想到状态 表示当前填 列, 行和为 , 行和为 , 行和为 。然后发现 是可以互相计算的,可以省掉两维。然后就是单次 的dp。且一次dp只能算出一个 。
然后我的辣鸡思路:
考虑如果只能填 的话,每一行都填了两个 ,我们把这两列对应的点连边,最后一定连出来好多环。但是要求是不能有自环。我们只要统计出这样的连边方式之后,再乘一个阶乘(每条边在哪一行连的),就是只能填 的答案了。设 表示 个点的连边方式。
长度为 的环没方向,而大于等于 的环则有方向,我们要统计的是无向的环,所以除二。
然后弄一下EGF发现这就是一个 的形式,求逆nlogn就可以了。
题解这部分是直接设的 表示 矩阵只填 的方案,大同小异,也是推出来一个 。
我们有了只填 的答案之后,单独考虑一下填 发现如果有一格填了 ,我们可以直接把这行这列删掉。然后枚举一下填了几个 之后也是一个卷积的式子,不再赘述。
发现数据范围这么大,可以直接猜标算做法:一遍 dp,直接求出所有 的答案。
然后我们只能设 表示 的矩阵的答案了。接下来就是神仙的构造映射。
还是考虑最后一列填的情况,如果它填了一个 ,那挺好说,可以直接删掉最后一列和所在行,。
如果它填了两个 ,那真就不太好说了。。
这里 是最后一列的两个 , 与 , 与 同行, 与 , 与 同列。
我们现在仍然是考虑删掉 ,这样才能缩小规模。这时 所在行都少了 ,怎么补上让它重新成为一个合法方案?直觉告诉我们应该把 移到同一行。发现这样确实没有影响更多的行和列,又重新成为了一个合法方案。
而 如果在同一列呢?那么我们也是把它们移到同一行:变成了一个 。
发现这个转移貌似还要分情况,于是我们重新定义状态: 表示最后一列是两个 的方案数, 表示最后一列是一个 的方案数。
然后 不用说。
还是回到上面的讨论,融合后的这一行应该放到哪??
发现这行放到哪其实并不重要(但是所有映射方案要放到同一行,这样才能合法地构造映射)。因为它对方案的影响相当于是钦定了某一行有两个 或一个 。
然后我们就考虑写转移方程式了。先枚举一下这两个 在哪两行,有一个组合数。然后我们关注的就是与它们对应的 在哪列。如果它们在不同列,就是钦定某一行有两个 。而它们一上一下有两种情况,所以应该乘二。而若它们在同列,则钦定了某一行有一个 。发现钦定某行情况和钦定最后一列情况其实是等价的。
然后就有了递推式:
就可以 递推了。
JZOJ6302 提高组
QAQ
有 组询问,每次询问给出 ,求 到 的排列,满足 ,且最长下降子序列长度最多为 的方案数。
首先找一下最长下降子序列长度最多为 的排列有什么性质。看起来没啥,那正难则反,如果一个排列具有大于等于 的下降子序列,那么我们随便从这个子序列的内部找一个位置,它前面有比它大的,后面有比它小的。然后我们发现这就是充要条件。
所以问题转化为我们要求对于每个数,要么它前面的都比它小,要么它后面的都比它大(比它小的都在前面)。
然后这种dp的套路就是要么从大到小枚举数要么从小到大枚举数嘛。
这里是都可以的啦,我是从大到小枚举的,式子长这样:
。
其中 表示现在限制只能在第 个数后及之前插入数的方案数。
因为如果插入到第 个数后,那么对后面产生的限制仍是只能在第 个数后及之前。
如果插入到最前,那么整体往后错一位。
然后考虑还有 的限制呢。
分类讨论一下,如果 ,那么比 小的都得在 前,大的都得在后。这时两边无关,可以分别统计,再相乘。
如果 ,发现 左边一定会有比 大的。那么我们只能限制比 小的都在 左边。那么我们到插入 之后比 小的都会插入到它左边,排名在后面增加的数目就固定了(),那么在插入 时它的排名也应固定,使得最后它可以到达第 个。
的发现如果还这么dp不太容易处理了,一种方式是再写一个从小到大插数的dp。。不过不用这么傻,我们让 ,这时容易发现和原限制是等价的。又转化为 。
我们现在有了单次 的做法。
没啥思路,打个表吧。
发现没有 限制时的答案数列竟然是卡特兰数!
然后想为什么会是卡特兰数。它与网格有关系,猛然发现这dp就像是一个网格游走!
然后发现这个转移不太标准,构造一个 ,它就变得很标准了。然后又发现固定 其实是固定了路径要经过哪个点。然后就对这个点之前和之后分别统计,再相乘即可。翻折法统计。
#include<bits/stdc++.h>
using namespace std;
const int N=2e7+50,mod=1e9+7;
int n,x,y,f[N],g[N],T,J[N],I[N],inv[N];
int C(int n,int m){return m<0||n<m?0:1ll*J[n]*I[m]%mod*I[n-m]%mod;}
int calc(int n,int m){
if(n>=m)return (C(n+m,n)-C(n+m,n+1)+mod)%mod;
}
int dp(int n,int x,int y){
if(!n)return 1;
if(!x)return 1ll*C(2*n,n)*inv[n+1]%mod;
return 1ll*(calc(n-y,n-x+1)-(n-y-1>=n-x+1?calc(n-y-1,n-x+1):0)+mod)*(C(y-1+x-1,y-1)-C(y-1+x-1,y-2)+mod)%mod;
memset(f,0,sizeof(int)*(n+1));f[1]=1;
for(int i=n-1;i;i--){
int sum=0;
if(i==y){
x-y+1;
for(int j=n-i;j>=x-y;j--)(sum+=f[j])%=mod;
memset(f,0,sizeof(int)*n);f[x-y]=sum;
}
else{
for(int j=n-i+1;j;j--)
(sum+=f[j])%=mod,f[j]=(sum+f[j-1])%mod;
}
}
int ret=0;
for(int i=1;i<=n;i++)(ret+=f[i])%=mod;
return ret;
}
int main(){
freopen("tg.in","r",stdin);
freopen("tg.out","w",stdout);
scanf("%d",&T);
J[0]=I[0]=inv[1]=1;
for(int i=2;i<N;i++)inv[i]=mod-1ll*mod/i*inv[mod%i]%mod;
for(int i=1;i<N;i++)J[i]=1ll*J[i-1]*i%mod,I[i]=1ll*I[i-1]*inv[i]%mod;
while(T--){
scanf("%d%d%d",&n,&x,&y);
if(x==y)printf("%d\n",1ll*dp(x-1,0,0)*dp(n-x,0,0)%mod);
else if(x>y)printf("%d\n",dp(n,x,y));
else printf("%d\n",dp(n,n-x+1,n-y+1));
}
return 0;
}
###CF1172F
某场div1的最后一题,赛时无人AC。。我当时打了对应的div2/cy
有一个长度为 的序列和一个模数 ,定义add_mod(x,y)返回 。有 次询问,每次给定 ,求对于初值为 ,对于在区间里的 顺次执行 z=add_mod(z,a[i]),求最后 的值。
考虑这种顺次考虑每个元素的形式,可以想到维护一个映射。对于一个区间有一个映射 ,表示如果从左端送进一个 在右端会出来一个 。这种做法之前在一个博弈论题目中用到过,那题是维护一个状压的状态,直接用数组映射的。
但是这里显然不能直接用数组映射。那么考虑可能是一个函数的形式。然后再观察就会发现对于长度为 的区间,经过这个区间最少就是不减 ,最多减 个 ,发现是一个分段函数,每一段都是一次函数,且最多有 段。
那么我们如果用一个线段树存每个区间的分段函数,则空间是 的,可以接受。
现在问题就是如何复合两个分段线性函数(线段树的信息合并)。
有一个比较显然的结论是对于 ,则 ,即大的数不可能减 的次数更少。单调性有了,我们只要对于每一个 求出最小的 使得 即可,有了每一段的左端点右端点也就有了。
然后考虑这个 次是分别在左右两边减的,一个很自然的思路就是枚举左边的第 段,和右边的第 段,如果能到达的话就去更新 。但是这样合并是 的。考虑可能有很多 和 不可达,那么可能可以用双指针优化。
有一个结论就是在两段分界的地方纵坐标相差 。这个是显然的。所以看起来相交的部分并不多?
然后我们再证明每段的横坐标跨度长度至少为 。我们考虑一个折线图表示到达每个位置时的 的大小。设 ,再设这个区间的最大前缀和的位置为 ,则 。然后慢慢增大 ,直到 所在横坐标的折线碰到了 这条直线。这时进入下一段,减了一个 ,pos以后的折线都向下平移 个单位。然后再增大 ,如果下一次仍然是 pos 碰到 ,则这一段的长度为 ,满足。否则一定在 前面的位置碰到,然后那个位置以后的折线向下平移, 就碰不到了。直到 再次碰到才会使得 增大,然后段的长度就为 。得证了。
所以当左边的函数两段分界的时候,可行的 最多只会减 。然后就可以双指针了。
#include<bits/stdc++.h>
#define LL long long
#define pb push_back
using namespace std;
const int N=1e6+50;
const LL inf=1e16;
int n,m,p;LL now,sum[N];
vector<LL>v[N*4];
int read(){
int x=0,c,f=1;
while(!isdigit(c=getchar()))c=='-'?f=-1:0;
while(isdigit(c))x=x*10+c-48,c=getchar();
return x*f;
}
void up(int x,LL S){
int L=x<<1,R=x<<1|1;
v[x].resize(v[L].size()+v[R].size()-1,inf);
for(int i=0,j=0;i<v[L].size();i++){
LL xl=v[L][i],xr=i==v[L].size()-1?inf:v[L][i+1]-1,yl=xl+S-1ll*i*p,yr=xr+S-1ll*i*p;
if(j)j--;
while(j<v[R].size()-1&&v[R][j+1]<=yl)j++;
for(;j<v[R].size()&&v[R][j]<=yr;j++)v[x][i+j]=min(v[x][i+j],max(xl,v[R][j]-S+1ll*i*p));
}
v[x][0]=-inf;
}
void build(int x,int l,int r){
if(l==r){sum[l]=sum[l-1]+read(),v[x].pb(-inf);v[x].pb(p-(sum[l]-sum[l-1]));return;}
int mid=(l+r)>>1;
build(x<<1,l,mid);build(x<<1|1,mid+1,r);
up(x,sum[mid]-sum[l-1]);
}
void query(int x,int l,int r,int ql,int qr){
if(l>=ql&&r<=qr){now+=sum[r]-sum[l-1]-1ll*(upper_bound(v[x].begin(),v[x].end(),now)-v[x].begin()-1)*p;return;}
int mid=(l+r)>>1;
if(ql<=mid)query(x<<1,l,mid,ql,qr);
if(qr>mid)query(x<<1|1,mid+1,r,ql,qr);
}
int main(){
n=read();m=read();p=read();
build(1,1,n);
for(int i=1,l,r;i<=m;i++){
l=read();r=read();
now=0;query(1,1,n,l,r);
printf("%lld\n",now);
}
return 0;
}
[AGC018F] Two Trees
我吹爆!我自己想出了某场AGC的最后一题!泪目
给定两棵 个节点的有根树,要求给每个编号一个权值,使得两棵树中每棵子树和都为 或 。判定有无解,如果有解给出任意一组解。
首先发现每个点需要填的数的奇偶性已经确定了(根据儿子个数)。而如果两棵树确定出的奇偶性有矛盾,则显然无解。
然后就是尽情地发挥聪明才智想构造了。靠直觉发现每个数都不能填得离 或 太远,因为叶子一定得填 或 ,要尽量保证合法。
于是对于有偶数个儿子的点我们希望它所有儿子的子树和加起来是 ,这样相当于对这个节点没有限制,又是一个叶子。这样有什么好处?这样一个点的子树和就是它自己的点权,又给自己提供了方便!
那么只需要所有儿子点权加起来是 就好了。再次发挥聪明才智,手玩了一下发现这个貌似挺好构造的,因为约束挺松的啊。偶数个节点加起来是 比较难做,那直接让它们两两之和为 好了!然后就是建了一些边,要求边两端的颜色不同。这个是经典染色问题,而且一个点最多只会在其中一棵树连一条约束边,在另一棵树连一条约束边,显然构成了二分图。于是直接做就好了。
而奇数个儿子的点就让它为 ,再送上去一个儿子就好了...
#include<bits/stdc++.h>
#define pb push_back
using namespace std;
const int N=1e5+50;
int n,r1,r2,ans[N],f1[N],f2[N],id[N];
vector<int>v1[N],v2[N],vv[N];
void dfs1(int x){
for(int i=0;i<v1[x].size();i++)dfs1(v1[x][i]);
for(int i=1,y,z;i<v1[x].size();i+=2)
y=id[v1[x][i-1]],z=id[v1[x][i]],vv[y].pb(z),vv[z].pb(y);
if(v1[x].size()&1)id[x]=id[v1[x].back()],ans[x]=0;
}
void dfs2(int x){
for(int i=0;i<v2[x].size();i++)dfs2(v2[x][i]);
for(int i=1,y,z;i<v2[x].size();i+=2)
y=id[v2[x][i-1]],z=id[v2[x][i]],vv[y].pb(z),vv[z].pb(y);
if(v2[x].size()&1)id[x]=id[v2[x].back()],ans[x]=0;
}
void dfs(int x){
for(int i=0,y;i<vv[x].size();i++)
if(ans[y=vv[x][i]]>1)ans[y]=-ans[x],dfs(y);
}
int main(){
scanf("%d",&n);
for(int i=1;i<=n;i++)ans[i]=2;
for(int i=1,x;i<=n;i++){
scanf("%d",&x);
if(~x)v1[x].pb(i);else r1=i;
}
for(int i=1,x;i<=n;i++){
scanf("%d",&x);
if(~x)v2[x].pb(i);else r2=i;
}
for(int i=1;i<=n;i++)if((v1[i].size()&1)^(v2[i].size()&1))puts("IMPOSSIBLE"),exit(0);
for(int i=1;i<=n;i++)id[i]=i;dfs1(r1);
for(int i=1;i<=n;i++)id[i]=i;dfs2(r2);
for(int i=1;i<=n;i++)if(ans[i]>1)ans[i]=1,dfs(i);
puts("POSSIBLE");
for(int i=1;i<=n;i++)printf("%d ",ans[i]);
return 0;
}
这题还有一个思路,不过很难想到。。。考虑利用欧拉回路解决。首先把两棵树的根都连向一个虚点(这样所有点都有父亲了),然后对于偶数个儿子的节点在两棵树的对应节点间连边。发现这样构出的图每个点都是偶度数,且联通,所以有欧拉回路。然后跑出欧拉回路。对于偶数个儿子的节点如果从左树走到右树则赋值为 ,否则赋值为 。这样的合法性比较显然。对于某一棵子树,进出这棵子树的边应该数量是相等的。而它的父亲边没有权,其他进出的边都给这个子树带了 的权,加起来一定是 或 。这个思路太强了Orz。
[AGC016F] Games on DAG
给定一张 个点 条边的DAG,边只会从编号小的连向编号大的。图上的游戏定义为在 号节点各放一个石子,每次操作可以使某个石子沿边移动一次,不能操作者失败。现在可以在图上删掉一些边,问 种图中先手必胜的方案数。
这个显然是要考虑SG函数的。先手必胜当且仅当 的SG值不同。然后就不会了。
考虑这样一个事情:SG函数的计算的基础操作是 。那么它有什么性质呢?考虑一点点地确定每个点的SG值。先确定SG为 的集合。这个集合需要满足集合之间没有连边,它的补集中每个点都向这个集合有连边。考虑在DAG上构造这个集合的过程,发现有且仅有一个这样的集合,且与SG为 的集合对应。对于其他的点,SG值一定大于等于 。之后,这些SG值等于 的点对于其他的点就没有影响了。而剩下的点之间的关系又像是回到了最开始的情况( 顶替了 的位置,以此类推)这给我们一种递归子状态的感觉,可以借此设计DP了。
SG不同的方案数不好计算,那么正难则反,计算SG值相同的方案数。
要么都是 ,要么都不是 。于是枚举整张图SG是 的集合,限制 必须同属一边。这时需要满足上述提到的性质,就计算一下方案数即可。然后需要子状态,就DP一下即可。复杂度
#include<bits/stdc++.h>
using namespace std;
const int N=20,M=5e4+50,mod=1e9+7;
int n,m,f[M],mx,b[N],c[N],pw[M],bit[M];
int main(){
scanf("%d%d",&n,&m);mx=1<<n;f[0]=pw[0]=1;
for(int i=1;i<=m;i++)pw[i]=pw[i-1]*2%mod;
for(int i=1;i<mx;i++)bit[i]=bit[i>>1]+(i&1);
for(int i=1,x,y;i<=m;i++){
scanf("%d%d",&x,&y);x--;y--;
b[x]|=1<<y;c[y]|=1<<x;
}
for(int i=1;i<mx;i++){
if((i&1)^(i>>1&1))continue;
if(i&1){
for(int j=i;j;j=(j-1)&i){
if((j&1)^(j>>1&1))continue;
int dat=1,c2=0;
for(int k=0;k<n;k++)if((i^j)>>k&1){
int c1=bit[b[k]&j];c2+=bit[c[k]&j];
dat=1ll*dat*(pw[c1]-1)%mod;
}
f[i]=(f[i]+1ll*f[i^j]*dat%mod*pw[c2])%mod;
}
}
else{
int c1=0;
for(int j=0;j<n;j++)if(i>>j&1)c1+=bit[b[j]&i];
f[i]=pw[c1];
}
}
cout<<(pw[m]-f[mx-1]+mod)%mod;
return 0;
}
CF1349D
CF1349是xtq场,是众多大佬的滑铁卢。。场上貌似只有个位数做出这个D,tourist惨遭安排到top4...
有 个人,每人有 个饼干,每次在所有饼干中随机一个,再随机一个除持有者之外的人,把饼干给他。问期望多少次之后所有饼干会在同一个人手上。
一个非常naive的想法是设 表示 这个状态的期望步数,像随机游走一样列方程,再解方程。然而变量太多。不过我们可以尝试去“构造”这个 。尝试让整个 分为所有部分的贡献,即 。然后尝试求出合法的 。
然后根据转移过程构造关于 的恒等式,再提取与每个 相关的部分,它们一般长得格式一样(不一样大概就不能用这种方法了),于是关于 的方程就出来了。它如果可以快速求那么我们就解决这个问题了。具体可以看这个。这里提到我们不一定局限与 就是期望步数,它只要满足递推关系造成的等式即可。也就是目标状态的 值不一定为 ,最后只需减去目标状态值即可。这样可能会对求解 有所帮助。在CF1025G中有所体现。
发现这是一个被总结过的东西:https://www.cnblogs.com/TinyWong/p/12887591.html
CF1349F
史上最牛逼的题。只有观赏用途。题解
这里需要注意的是,后面看得云里雾里的二元生成函数和拉格朗日反演,其实是金策论文中例题14的trick。虽然题目中的式子更毒瘤,不过思想是一样的。
模拟赛题
链接,这题是算期望的好题,其中运用了多种技巧,可能与UR某题有类似之处
[SDOI2019]世界地图
这题是最小生成树神题。
ARC076D Exhausted?
这题真是二分图匹配神题。
有 张凳子, 个人,每个人能坐的凳子是一段前缀和一段后缀。求最多能坐下多少人。
首先转化为二分图匹配模型。然后有两种做法。
可以直接考虑贪心的思路来求最大匹配,即通过恰当的遍历方式使得增广路要么没有要么很容易找。
具体来说,我们首先有一个结论是坐在前缀中的人构成了一段前缀,坐在后缀中的人构成了一段后缀。证明可以考虑交换。这样的话,如果我们决定了哪些人坐在前缀,他们就对于坐在后缀的人没有影响了。于是考虑先决定哪些人坐在前缀,按 从小到大枚举,能坐就坐,否则拿出 最小的一个人让他坐在后缀。然后再安排坐在后缀的人即可。如果我们模拟一下匈牙利算法就可以发现这是正确的。
还有一种是根据hall定理的推论:二分图的最大匹配为 ,其中 是其中一个部点, 是 的子集, 是 的邻居集合。证明可以看这里,与hall定理证法一样,就是考虑反证,然后根据这个性质可以不断地扩大考虑的集合,直到全集,导出矛盾。
然后我们就可以考虑计算这个式子。因为 是一些区间的并,考虑枚举这个并,然后选尽可能多的区间使得是这个并的子集即可。枚举左端点,数据结构维护。
我尝试了一会这两个做法是否等价,结果发现它们似乎正好是相反的。因为前一种做法是想让 大, 小,而后一种却想让 小, 大。于是发现它们是互为对偶问题。确实,hall定理就是在求二分图网络流建图的最小割嘛!!!真是美妙。
CCO '20 P6 - Shopping Plans
有 个集合,共有 个元素,每个元素都有一个权值,一次合法的选择要满足对于第 个集合选出的元素个数在 ,代价为权值和。求合法选法中前 小的代价。
这题有弱化版,这两题看起来一样,实际上usaco的数据范围更弱,有一种二分+搜索的暴力做法。
弱化版是 。
这种题的思路是要构造一棵状态树,然后要满足父亲的权值比儿子权值小。于是我们扩展到一个状态就把它的所有儿子扔进堆里,每次取出堆顶。于是关键就是构造这棵树了。
子问题1
首先考虑 ,那么就是每个集合选一个数。先把每个集合内部排序。把每个集合选择了第几个元素记为一个向量,则容易想到我们对于一个向量,可以让它的某一维加 的向量当它的后继。不过这样显然不是树,那么我们让集合之间有序,对于一个向量 x,设它最大的不是 的位置是 ,那么接下来只能在 及之后加 。这样就可以保证每个状态有唯一的前驱。而从根到某节点的路径就是从 号集合顺次加 。不过这样有一个问题,就是一个点的儿子太多了。于是我们扩展不过来,就会 T 掉。那么要减少儿子数。容易发现一个状态的儿子间也会有偏序关系。因为大多数儿子都是某维从 变 ,那么把所有集合按从 到 会增加的代价排序,就可以让儿子转移到儿子了(其实也是改造了一下树的结构)。
子问题2
再来解决一个子问题,就是有 的限制,但是只有一个集合。
这时我们还是仿照上面的做法,在状态见连边建树。先把集合排序变为序列。我们如果把状态之间的转移看作一段元素平移了,那么转移其实也不是那么难。对于一个状态,我们关注它最靠右的被选择的连续段,考虑把这段的一个后缀向右平移一格。不过注意我们这样的操作不能改变选择元素的个数。于是还要加上这样的转移:如果所有被选的元素是序列的前缀,那么可以把下一位也选上(还要注意 的限制)。这样显然操作序列和状态是一一对应的。不过儿子仍然很多。于是我们还是考虑儿子间的偏序:发现向右平移的元素越少增量越少。这样就可以在儿子间转移了。
现在来解决原问题:我们可以把考虑把子问题1中集合中的数换成子问题2中的状态。外层仍然按子问题1做,而不同的地方在于我们在子问题1中的状态转移只是某个数++,在这里就是要在子问题2中找到后继状态。而排序的参数也相应的变成了每个“子问题2”的最优解和次优解的差值。
于是设计好状态就可以做了。不过细节很多,主要是 的时候很坑。
#include<bits/stdc++.h>
#define LL long long
#define pb push_back
using namespace std;
const int N=2e5+50;
int n,k,nn,val[N],m,l[N],r[N],p[N],c[N];LL sum;
vector<int>v[N],vv[N];
bool cmp(int x,int y){return val[x]<val[y];}
struct node{
LL sum;int x,num,p,fa,len;
bool friend operator <(node a,node b){return a.sum>b.sum;}
};
priority_queue<node>q;
void to(int y,LL sum){
if(!l[y]){q.push(node{sum+val[y],y,1,1,1,1});return;}
q.push(node{sum+val[y],y,l[y],l[y],1,l[y]+1});
if(l[y]^r[y])q.push(node{sum+v[y][l[y]],y,l[y]+1,1,1,l[y]+1});
}
int main(){
scanf("%d%d%d",&m,&n,&k);
for(int i=1,x,y;i<=m;i++)scanf("%d%d",&x,&y),vv[x].pb(y);
for(int i=1,x,y;i<=n;i++){
scanf("%d%d",&x,&y);y=min(y,(int)vv[i].size());
if(!x&&!y)continue;
if(y<x){
for(int j=1;j<=k;j++)puts("-1");exit(0);
}
if(vv[i].size()^x)v[++nn]=vv[i],l[nn]=x,r[nn]=y;
else for(int j=0;j<x;j++)sum+=vv[i][j];
}
for(int i=1;i<=nn;i++){
sort(v[i].begin(),v[i].end());
val[i]=v[i][l[i]]-(l[i]?v[i][l[i]-1]:0),p[i]=i;
for(int j=0;j<l[i];j++)sum+=v[i][j];
}
n=nn;sort(p+1,p+n+1,cmp);
for(int i=1;i<=n;i++)vv[i]=v[p[i]],c[i]=l[p[i]];
for(int i=1;i<=n;i++)v[i]=vv[i],l[i]=c[i],c[i]=r[p[i]];
for(int i=1;i<=n;i++)r[i]=c[i],val[i]=v[i][l[i]]-(l[i]?v[i][l[i]-1]:0);
q.push(node{sum,0,0,1,1,0});
for(int i=1;i<=k;i++){//sum,x,num,p,fa,len
if(q.empty()){puts("-1");continue;}
node u=q.top();q.pop();int x=u.x,num=u.num,p=u.p,fa=u.fa,len=u.len,y=x+1;
LL sum=u.sum;printf("%lld\n",sum);
if(x<n){
to(y,sum);
if(l[x]&&num==l[x]&&p==l[x]&&len==l[x]+1)to(y,sum-val[x]);
if(!l[x]&&num==len&&num==1)to(y,sum-val[x]);
}
if(num==len&&num<r[x])q.push(node{sum+v[x][num],x,num+1,1,1,len+1});
if(len<v[x].size())q.push(node{sum+v[x][len]-v[x][len-1],x,num,num,p,len+1});
if(p>fa)q.push(node{sum+v[x][len-(num-p)-2]-v[x][len-(num-p)-3],x,num,p-1,fa,len});
}
return 0;
}
// 5 2 7
// 1 5
// 1 3
// 2 3
// 1 6
// 2 1
// 0 0
// 0 1
要注意的是这种问题就是k短路的模型。就是那种复杂度正常的可持久化堆的做法...
51nod1847 奇怪的数学题
给出 ,求 ,其中 表示 的次大公约数。如果最大公约数为 则值为 。对 取模。
反演一波可以得到
于是转化成求 和 的前缀和在所有 处的值。 可以杜教筛,而 我们可以把贡献分为质数和合数,质数的贡献就是 ,合数的贡献可以在它的mindiv处统计。套上min25筛即可。而计算幂和时没有逆元不好处理,考虑 比较小,可以考虑暴力 。把幂和用斯特林数转化为下降幂,下降幂前缀和很容易计算。逆元的问题只要找到它的倍数先除再乘即可。
#include<bits/stdc++.h>
#define ui unsigned int
using namespace std;
const int N=1e6,K=60;
int n,k,p[N],tot,sq,st[N],tp;bool vis[N];ui phi[N],val[N],pw[N],fk[N],f0[N],S[K][K],ans,spk[N],sum[N];
ui power(ui x,int y){
ui z=1;
for(;y;y>>=1,x*=x)if(y&1)z*=x;
return z;
}
ui calc(int n){
ui ret=0;
for(int i=1;i<=min(n,k);i++){
int p=(n+1)%(i+1);ui dat=S[k][i];
for(int j=0;j<i+1;j++,p--){
if(p)dat*=(n+1-j);
else dat*=(n+1-j)/(i+1);
}
ret+=dat;
}
return ret;
}
int Id(int d){return d>sq?n/d+sq:d;}
int main(){
scanf("%d%d",&n,&k);phi[1]=S[0][0]=1;sq=sqrt(n);
for(int i=1;i<=k;i++)
for(int j=1;j<=i;j++)
S[i][j]=S[i-1][j-1]+S[i-1][j]*j;
for(int i=2;i<N;i++){
if(!vis[i])p[++tot]=i,phi[i]=i-1,pw[i]=power(i,k);
for(int j=1,y;j<=tot&&(y=p[j]*i)<N;j++){
vis[y]=1;pw[y]=pw[i]*pw[p[j]];
if(i%p[j])phi[y]=phi[i]*(p[j]-1);
else{phi[y]=phi[i]*p[j];break;}
}
}
for(int i=1;i<=tot;i++)spk[i]=spk[i-1]+pw[p[i]];
for(int i=2;i<N;i++)phi[i]+=phi[i-1];
int s=1;while(n/(s+1)>=N)s++;
for(int i=s;i;i--){
int m=n/i,l=2,r,d;val[i]=1ll*m*(m+1)/2;
for(;l<=m;l=r+1){
d=m/l,r=m/d,
val[i]-=(r-l+1)*(d<N?phi[d]:val[r*i]);
}
}
for(int l=1,r,d;l<=n;l=r+1)
d=n/l,r=n/d,fk[Id(d)]=calc(d)-1,f0[Id(d)]=d-1,st[++tp]=d;
for(int i=1;i<=tot;i++){
int sq=p[i]*p[i];if(sq>n)break;
for(int j=1;p[i]*p[i]<=st[j];j++){
int id=Id(st[j]),iid=Id(st[j]/p[i]);
fk[id]-=pw[p[i]]*(fk[iid]-spk[i-1]),
f0[id]-=f0[iid]-(i-1);
sum[id]+=fk[iid]-spk[i-1];
//这题函数特殊之处在于只要知道了一个数的mindiv,剩下的部分不用得到所有素数幂的信息也可以直接计算。于是就不需要搜索的那部分了。
}
}
for(int i=1,d;i<=tp;i++)d=Id(st[i]),sum[d]+=f0[d];
for(ui l=1,r,d,la=0,v;l<=n;l=r+1){
d=n/l;r=n/d;v=sum[Id(r)];
ans+=(v-la)*(2*(d<N?phi[d]:val[r])-1);la=v;
}
cout<<ans;
return 0;
}
[ZJOI2016]线段树
有长度为 的序列和 次随机的操作,每次操作等概率从 个区间中选择一个区间,把区间内的所有数改为区间内最大值。对每个数输出它最后值的期望。
玩了玩发现可能与笛卡尔树有关。不过这里可能会有重复值,最大值不唯一。那么我们考虑一棵广义的笛卡尔树,每次找到一个区间内的所有最大值的位置,然后将它们把区间分成的子区间递归(也就是说这个东西不一定二叉)。不过这个东西也可以改造成二叉,只要我们把每个值变成(值,位置)的pair,这样最大值就唯一了。
然后发现一个数最后只可能会成为它在笛卡尔树上的祖先。然后考虑它最后变成了哪个祖先,在这个节点上记上贡献。不过发现计算最后恰好在某个节点太难算,于是考虑差分一下,每个节点的贡献拆成它到根的差分序列的和,即设根到这个点的路径为 ,然后贡献变成了 。于是对于一个点,它子树内的点都会对它造成贡献,即我们现在的状态变成了 的数的贡献。然后我们再考虑贡献转移就行了。这题太神了说不清楚。
转移:
突然发现这个转移如果是用那种多叉的笛卡尔树来理解是比较好理解的!
这个 的状态是说当前这个节点的子树代表了序列的 ,然后因为 都比这棵子树的根要大,所以如果操作区间跨过 的区间内和区间外,那么 内部的那部分的值就会变大,然后并到 的某个祖先节点的内部(因为多叉的结构,多个数是可以在同一节点的),然后这棵子树就缩了,所以它会转移到更小的区间!然后转移就很好解释了,要么操作区间毫无影响( )要么缩了一部分,要么缩没了,这部分不用转移。
#include<bits/stdc++.h>
using namespace std;
const int N=440,mod=1e9+7,inf=2e9;
int n,m,a[N],s[N],g[N][N],f[2][N][N],p,q=1;
int read(){
int x=0,c;
while(!isdigit(c=getchar()));
while(isdigit(c))x=x*10+c-48,c=getchar();
return x;
}
int main(){
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++)a[i]=read();a[0]=a[n+1]=inf;
for(int i=1;i<=n;i++)s[i]=s[i-1]+i;
for(int i=1;i<=n;i++)
for(int j=i;j<=n;j++)
g[i][j]=s[i-1]+s[n-j]+s[j-i+1];
for(int i=1;i<=n;i++){
for(int j=i,mx=0,d;j<=n;j++){
mx=max(mx,a[j]);d=min(a[i-1],a[j+1]);
if(mx<d)f[0][i][j]=mx-(d^inf?d:0);//这样说明它是笛卡尔树上的节点,然后计算一下它的贡献,即与父亲的差分。
}
}
for(int k=1;k<=m;k++){
swap(p,q);memset(f[p],0,sizeof(f[p]));
for(int i=1;i<=n;i++)
for(int j=i;j<=n;j++)
f[p][i][j]=1ll*f[q][i][j]*g[i][j]%mod;
for(int i=1;i<=n;i++)
for(int j=n,z=0;j>=i;j--)
(f[p][i][j]+=z)%=mod,z=(z+1ll*f[q][i][j]*(n-j))%mod;
for(int j=1;j<=n;j++)
for(int i=1,z=0;i<=j;i++)
(f[p][i][j]+=z)%=mod,z=(z+1ll*f[q][i][j]*(i-1))%mod;
}
for(int k=1;k<=n;k++){
int ans=0;
for(int i=1;i<=k;i++)
for(int j=k;j<=n;j++)
(ans+=f[p][i][j])%=mod;
printf("%d ",(ans+mod)%mod);
}
return 0;
}
P6585 中子衰变
这是某场洛谷月赛的神仙博弈题。这道题告诉我们,我们需要通过小数据手玩或打表来得知到底哪方必胜,然后需要构造合适的 循环不变式。SG函数就是一个非常优秀的循环不变式,而如果博弈问题更复杂,那么就需要自己想了。具体的洛谷题解写得很清楚。
[ZJOI2017]线段树
这题可能对会用zkw线段树的选手有极大优势。。。
给定一棵“广义线段树”,即每个节点的分割点都是输入的,不一定是中点。然后询问是给定 ,询问 [l,r] 在“线段树区间询问”时覆盖到的所有线段树节点与 的距离和。
这题的主要想法是考虑询问区间覆盖到的节点的特点。我们考虑线段树询问时只有一次会同时递归两边。这时是询问区间被截成了两段。于是在递归进的两棵子树中询问其实分别变成了 前缀 和 后缀。如果我们询问的是前缀,那么被覆盖的节点一定都是左儿子,是后缀的话就都是右儿子。然后就有一个想法。如果我们把每一个左儿子节点连向在它左边的第一个左儿子节点,这样我们就会发现:因为覆盖到的点都是左儿子,而且区间是连续的,所以我们会得到构造出的这棵树上的链。右儿子也是类似。于是我们首先要求出询问区间覆盖到了哪条链。对于 ,我们找到右端点为 的左儿子,然后倍增找到链的另一个端点即可。
那么我们找到了链,就可以把询问差分,变成了询问从根到一个点的路径上所有的点的贡献。这样我们就dfs的同时维护贡献即可。而距离就拆成 ,然后 用经典trick:每次把点到根的路径+1,然后询问就询问到根的路径上的和。这个东西我尝试了用树剖+线段树,它被卡常了。而我并不想写树剖+树状数组,然后又写了一个LCT。它就过了...
其实线段树仍有更多的性质,关于线段树上的距离和找到链等地方仍有更高妙的做法,不过仅仅我们挖掘出来的这些性质就足以做这道题了。
#include<bits/stdc++.h>
#define pb push_back
#define pii pair<int,int>
#define mp make_pair
#define LL long long
using namespace std;
const int N=4e5+50;
int n,m,tot,c[N][2],rt,pos[N],st[N],tp,ll[N],rr[N],lid[N],rid[N],d[N];LL ans[N];
vector<int>v[N];
int read(){
int x=0,c;
while(!isdigit(c=getchar()));
while(isdigit(c))x=x*10+c-48,c=getchar();
return x;
}
struct LCT{
#define lc c[x][0]
#define rc c[x][1]
int f[N],c[N][2],val[N],laz[N],sz[N];LL sum[N];
bool nrt(int x){return c[f[x]][0]==x||c[f[x]][1]==x;}
bool chk(int x){return c[f[x]][1]==x;}
void up(int x){
sum[x]=sum[lc]+sum[rc]+val[x];
sz[x]=sz[lc]+sz[rc]+1;
}
void push(int x,int d){
val[x]+=d;sum[x]+=1ll*d*sz[x];laz[x]+=d;
}
void down(int x){
if(nrt(x))down(f[x]);
if(laz[x])push(lc,laz[x]),push(rc,laz[x]),laz[x]=0;
}
void rotate(int x){
int y=f[x],z=f[y],k=chk(x),w=c[x][k^1];
if(nrt(y))c[z][chk(y)]=x;c[x][k^1]=y;c[y][k]=w;
f[f[f[w]=y]=x]=z;up(y);
}
void splay(int x){
down(x);
for(int y;nrt(x);rotate(x))
if(nrt(y=f[x]))rotate(chk(x)^chk(y)?x:y);
up(x);
}
void access(int x){
for(int y=0;x;x=f[y=x])splay(x),rc=y,up(x);
}
}T;
void build(int &x,int l,int r){
x=++tot;ll[x]=l;rr[x]=r;int mid;T.sz[x]=1;
if(l==r){pos[l]=x;return;}
if(l==0)mid=l;else if(r>n)mid=n;else mid=read();
build(c[x][0],l,mid),build(c[x][1],mid+1,r);
lid[mid]=c[x][0],rid[mid+1]=c[x][1];
T.f[c[x][0]]=T.f[c[x][1]]=x;
}
void change(int x,int y){T.access(x);T.splay(x);T.push(x,y);}
LL query(int x){T.access(x);T.splay(x);return T.sum[x];}
struct Tree{
vector<int>v[N];int f[N][20],cnt;LL sum;
vector<pii>q[N];
void build(int x,int o){
int y=c[x][o];
if(y){
v[st[tp]].pb(y);f[y][0]=st[tp];
for(int i=0;f[y][i];i++)f[y][i+1]=f[f[y][i]][i];
build(y,o);st[++tp]=y;build(c[x][o^1],o);
}
}
void dfs(int x){
if(x)change(x,1),cnt++,sum+=d[x];
for(int i=0;i<q[x].size();i++){
int id=q[x][i].second,y=q[x][i].first,k=1;
if(id<0)k=-1,id=-id;
ans[id]+=k*(sum+1ll*cnt*d[y]-2*query(y));
}
for(int i=0;i<v[x].size();i++)dfs(v[x][i]);
if(x)change(x,-1),cnt--,sum-=d[x];
}
}L,R;
int main(){
scanf("%d",&n);build(rt,0,n+1);
for(int i=1;i<=tot;i++)d[i]=d[T.f[i]]+1;
ll[0]=-1e9;rr[0]=1e9;
L.build(rt,0);tp=0;R.build(rt,1);
scanf("%d",&m);
for(int i=1,x,l,r;i<=m;i++){
scanf("%d%d%d",&x,&l,&r);x+=3;
int v=lid[r],u=v;
if(ll[v]>=l){
for(int j=19;~j;j--)if(ll[L.f[u][j]]>=l)u=L.f[u][j];
u=L.f[u][0];L.q[u].pb(mp(x,-i));L.q[v].pb(mp(x,i));
}
v=rid[l],u=v;
if(rr[v]<=r){
for(int j=19;~j;j--)if(rr[R.f[u][j]]<=r)u=R.f[u][j];
u=R.f[u][0];R.q[u].pb(mp(x,-i));R.q[v].pb(mp(x,i));
}
}
L.dfs(0);R.dfs(0);
for(int i=1;i<=m;i++)printf("%lld\n",ans[i]);
return 0;
}
bzoj4453 cys就是要拿英魂!
这题是好题!
给定一个字符串,每次询问一个区间内的字典序最大的子串的起始位置。
考虑询问区间的问题怎么做。这题没有强制在线我们就考虑离线做法。把询问按右端点排序,然后怎么做呢?
考虑如果一个串它的右边(比较串的起始位置)已经有一个串比它大了,那这个串就没有用了。进一步地,我们要维护一个单调的序列,把没有用的串都删掉。如果我们有这个东西,那么每次询问左端点就直接二分一下即可。
那么怎么维护呢?首先我们知道如果一个串被删那就是永久被删,因为如果一个串已经比它大那么往后接字符仍然比它大。我们考虑一个串 什么时候会被删,那就是 。
如果用后缀数组求lcp,那么这就是 的。如何优化呢?还是考虑到这个式子也有性质。因为这个式子是取min,所以如果 增加,那么 必须要减小才能更优。而因为 ,所以 也要增大才行。(考虑后缀树嘛,height的区间min嘛)如果我们设 是 之后第一个rk比它大的,式子变成了 。而 ,如果取到了 ,那么因为 所以不优。于是我们让它取 就行了。于是 。这样就构成了一棵树的结构,我们只需找到每个点的父亲即可。这个就直接单调栈即可。于是我们可以 得到每个点的删除时间,然后就随便set维护一下即可。好像还可以并查集,不过反正SA是瓶颈。
这题确实是跳出了字符串题的套路/qiang
#include<bits/stdc++.h>
#define pb push_back
#define pii pair<int,int>
#define mp make_pair
using namespace std;
const int N=2e5+50;
char s[N];int q,x[N],y[N],c[N],sa[N],n,m,rk[N],st[N],tp,h[N][20],lo[N],ans[N];bool vis[N];
vector<int>v[N],vv[N];
vector<pii>Q[N];
void getsa(){
m=128;
for(int i=1;i<=n;i++)c[x[i]=s[i]]++;
for(int i=1;i<=m;i++)c[i]+=c[i-1];
for(int i=n;i;i--)sa[c[x[i]]--]=i;
for(int k=1;k<=n;k<<=1){
for(int i=n-k+1,z=0;i<=n;i++)y[++z]=i;
for(int i=1,z=k;i<=n;i++)if(sa[i]>k)y[++z]=sa[i]-k;
for(int i=1;i<=m;i++)c[i]=0;
for(int i=1;i<=n;i++)c[x[i]]++;
for(int i=1;i<=m;i++)c[i]+=c[i-1];
for(int i=n;i;i--)sa[c[x[y[i]]]--]=y[i];
swap(x,y);x[sa[1]]=m=1;
for(int i=2;i<=n;i++)
x[sa[i]]=y[sa[i]]==y[sa[i-1]]&&y[sa[i]+k]==y[sa[i-1]+k]?m:++m;
if(m==n)break;
}
for(int i=1;i<=n;i++)rk[sa[i]]=i;
for(int i=1,j=0;i<=n;i++){
if(j)j--;
while(s[i+j]==s[sa[rk[i]-1]+j])j++;
h[rk[i]][0]=j;
}
for(int i=0;i<18;i++)
for(int j=1;j+(1<<i+1)-1<=n;j++)
h[j][i+1]=min(h[j][i],h[j+(1<<i)][i]);
}
int lcp(int x,int y){
int l=rk[x],r=rk[y];
if(l>r)swap(l,r);l++;
int ll=lo[r-l+1];
return min(h[l][ll],h[r-(1<<ll)+1][ll]);
}
void dfs(int x,int d){
vv[d].pb(x);vis[x]=1;
for(int i=0,y;i<v[x].size();i++)
y=v[x][i],dfs(y,min(d,x+lcp(x,y)));
}
set<int>se;
int main(){
scanf("%s",s+1);n=strlen(s+1);
for(int i=2;i<=n;i++)lo[i]=lo[i>>1]+1;
getsa();
for(int i=1;i<=n;i++){
while(tp&&rk[st[tp]]<rk[i])
v[i].pb(st[tp--]);
st[++tp]=i;
}
for(int i=n;i;i--)if(!vis[i])dfs(i,n+1);
scanf("%d",&q);
for(int i=1,l,r;i<=q;i++)
scanf("%d%d",&l,&r),Q[r].pb(mp(l,i));
for(int i=1;i<=n;i++){
se.insert(i);
for(int j=0;j<vv[i].size();j++)se.erase(vv[i][j]);
for(int j=0;j<Q[i].size();j++)
ans[Q[i][j].second]=*se.lower_bound(Q[i][j].first);
}
for(int i=1;i<=q;i++)printf("%d\n",ans[i]);
return 0;
}
一个数竞题
在坐标系中任取十个点,都存在一些不相交(可相切)的单位圆使得每个点都在一个圆内。
主要的思路是:这玩意看起来也不能构造,好像所有想法都行不通了...但是我们可以考虑一下让空间利用率尽可能大,即让所有圆排布得尽可能密。那么三个圆会形成品字形,其他的圆都无穷地往外接,这样可以计算得到圆的面积占了整个平面的 。诶,看起来和 有点关系了!然后我们考虑平移这个无穷的圆的图形,那么得到每个点被覆盖的概率是 ,十个点被覆盖的点数的期望就是 。如果每一种平移都存在一个点不在圆内,那么期望应该小于 。于是一定存在平移方式使得每个点都在一个圆内。得证。
(这个是数竞大佬给我讲的,然后我又想出一个做法,可能可以解决更多点数的问题)
CF311E Biologist
网络流复健题
有一个长度为 的 串,将第 个位置变为另外一个数字的代价是 。 有 个要求 每个要求的形式是 首先确定若干位置都要是 或者
然后给定这 个位置,如果些位置上都满足要求 那么就可以得到 元 某些要求如果失败了还要倒着给 元 问最终能够得到的最大利润。
这题有两种理解思路。首先我们可以考虑二元关系最小割。给每个数字和要求都建一个点,与 或 连分别代表是 或 满足/不满足,然后中间连一些 边来满足限制,麻烦地弄出来之后图长这样: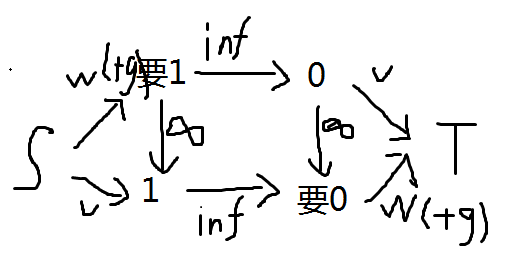
这中间我们经过了“最大转最小,把边取反”和“有负权边,两边加 “,最后得到的结果是 这张图的最小割。
然而我们发现这玩意的形式很像最大权闭合子图。那么如何理解?
这个最大权闭合子图的思路主要是这样的:我们考虑先把所有 变成 ,这些点的区别就在于点权正负了(原来是 变回 会加),这时所有的“要0”就都满足了,于是我们可以加上这些 和 。然后考虑我们想要去满足一些“要1”,这时它要求的点都要变,而一个点变了之后与它连接的“要0”就不能满足了。这就是这个图的含义。
我们选了一个节点具体是什么意思呢?
数:变成
“要1”:这个条件满足了
“要0”:这个条件不满足了
然后建出图发现跟这个图一模一样。
CF1284F
这题直接导致我去肝了拟阵交。。不过还是值得的,拟阵交确实很优美。
这题里有完美匹配的结论其实是拟阵中的一个经典结论。它是用强基交换定理归纳证明的。我们可以考虑直接用这个思路归纳构造解。
那么现在问题就是找出 和 都是树。可以直接LCT莽,但是我们想要简单的做法。
发现如果 中 的叶子,那么任何一个以 为端点的链都会覆盖这条边。这就大大简化,我们只需要找到 中在 这条链上且端点为 的边。找到这条边之后只需要缩起来。我们可以用并查集维护。
#include<bits/stdc++.h>
#define pb push_back
using namespace std;
const int N=3e5+50;
int n,cnt,f[N][18],d[N],fa[N],id[N],s[N];
vector<int>v1[N],v2[N];
void dfs1(int x,int ff){
for(int i=0;i<17;i++)f[x][i+1]=f[f[x][i]][i];
for(int i=0,y;i<v1[x].size();i++)if((y=v1[x][i])!=ff)
f[y=v1[x][i]][0]=x,d[y]=d[x]+1,dfs1(y,x);
}
int find(int x){return fa[x]==x?x:fa[x]=find(fa[x]);}
void merge(int x,int y){
x=find(x);y=find(y);
if(s[x]>s[y])swap(x,y);
fa[x]=y;s[y]+=s[x];id[y]=d[id[y]]<d[id[x]]?id[y]:id[x];
}
void dfs2(int x,int ff){
for(int i=0,y;i<v2[x].size();i++)
if((y=v2[x][i])!=ff)dfs2(y,x);
if(!ff)return;
int fx=id[find(x)],p=ff;
for(int i=17;~i;i--)
if(d[id[find(f[p][i])]]>d[fx])p=f[p][i];
if(id[find(f[p][0])]!=fx)p=fx;
merge(p,f[p][0]);
printf("%d %d %d %d\n",p,f[p][0],x,ff);
}
int main(){
scanf("%d",&n);
for(int i=1,x,y;i<n;i++)
scanf("%d%d",&x,&y),
v1[x].pb(y),v1[y].pb(x);
for(int i=1,x,y;i<n;i++)
scanf("%d%d",&x,&y),
v2[x].pb(y),v2[y].pb(x);
printf("%d\n",n-1);
for(int i=1;i<=n;i++)id[i]=fa[i]=i,s[i]=1;
dfs1(d[1]=1,0);dfs2(1,0);
return 0;
} #include<bits/stdc++.h>
#define pb push_back
using namespace std;
const int N=3e5+50;
int n,cnt,f[N][18],d[N],fa[N],id[N],s[N];
vector<int>v1[N],v2[N];
void dfs1(int x,int ff){
for(int i=0;i<17;i++)f[x][i+1]=f[f[x][i]][i];
for(int i=0,y;i<v1[x].size();i++)if((y=v1[x][i])!=ff)
f[y=v1[x][i]][0]=x,d[y]=d[x]+1,dfs1(y,x);
}
int find(int x){return fa[x]==x?x:fa[x]=find(fa[x]);}
void merge(int x,int y){
x=find(x);y=find(y);
if(s[x]>s[y])swap(x,y);
fa[x]=y;s[y]+=s[x];id[y]=d[id[y]]<d[id[x]]?id[y]:id[x];
}
void dfs2(int x,int ff){
for(int i=0,y;i<v2[x].size();i++)
if((y=v2[x][i])!=ff)dfs2(y,x);
if(!ff)return;
int fx=id[find(x)],p=ff;
for(int i=17;~i;i--)
if(d[id[find(f[p][i])]]>d[fx])p=f[p][i];
if(id[find(f[p][0])]!=fx)p=fx;
merge(p,f[p][0]);
printf("%d %d %d %d\n",p,f[p][0],x,ff);
}
int main(){
scanf("%d",&n);
for(int i=1,x,y;i<n;i++)
scanf("%d%d",&x,&y),
v1[x].pb(y),v1[y].pb(x);
for(int i=1,x,y;i<n;i++)
scanf("%d%d",&x,&y),
v2[x].pb(y),v2[y].pb(x);
printf("%d\n",n-1);
for(int i=1;i<=n;i++)id[i]=fa[i]=i,s[i]=1;
dfs1(d[1]=1,0);dfs2(1,0);
return 0;
}
听说树上的并查集是可以做到线性的,但是比线性rmq还要复杂,而且常数很大,比带反阿克曼的还要慢。所以其实它除了理论价值以外没有什么用,我们平时就把反阿克曼看成常数就行了/cy
我还考虑了一下别的拟阵能否做类似的题。首先考虑了线性基,不过线性基没有一个很好的结构,确实非常困难。而且它需要占用的空间也很大。图拟阵确实是很优秀的拟阵,它拥有很好的结构。
【清华集训2016】数据交互
- 给定一棵树,维护一个带权链的集合,支持加入链删除链,询问在树上随便选择一条链(不一定在集合内),最大化与这条链有公共点的集合中的链的权值和。
首先简单的结论是两链相交必定其中一个LCA在另一个上。
我们把树重链剖分,把所有链按LCA所在重链分类。我们考虑对每一类求出最大值,然后再整体取max。对于一条链,一定是覆盖了这条重链的一个区间,然后在两端伸下去。而我们还要最大化值,可以想到这就是最大子段和问题。然而一个区间 的权值是形如这样的:。 是这个位置往下伸的链的最大权值。可以从它下面的重链转移过来。而一条链的 处还有额外的贡献,所以我们要支持链加 ,单点加 ,维护区间最大权值和前缀最大权值。注意 是从这个位置伸出的所有重链的前缀最大值取max,于是用multiset维护,整体的取max也是用multiset维护。而且还要注意:如果在最高的重链上只有一个点,那么是伸出了最大和次大的两条链,要特别处理一下。。代码挺难写的。挺长的不贴了,在uoj。
实现上的技巧:如果链加可能比较恶心,我们可以从LCA处断开,做两次就行了。
CF1286C
交互题,有一个字符串 ,你不知道它是啥,有三次询问机会,每次给出 ,会返回 的所有子串(位置不同串相同也算不同),所有子串打乱顺序,每个串的字符也打乱顺序。还要求返回的总子串个数不能超过 。最后要猜出串是什么。
考虑我们询问整串能得到什么信息。因为串已经打乱,所以基本只能得到关于字符个数的信息了。我们可以得到这样的数组:,表示所有长度为 的子串中字符 出现的次数和。那么画画图发现由 和 我们就可以得到 位置上的字符了(不知道哪个是哪个),类似地,我们可以得到所有对称位置的字符。于是现在只要求出前一半的字符串就可以得到整个了。
看起来可以类似地递归做,但是这样询问次数就会达到 。考虑暴力一点的做法,设 ,询问 和 。那么对所有长度 考虑在 中数量比在 中多的那个串。这个串一定是 的长度为 的后缀。于是推过去即可得到整个串。这样返回总子串数约等于 大概是 ,所以这题就结束了。